Complex financial crimes are hard to detect primarily because data related to different pieces of the overall puzzle are usually distributed across a network of financial institutions, regulators, and law-enforcement agencies. The problem is also rapidly increasing in complexity because new platforms are emerging all the time that facilitate the transfer of value across a range of industries. These include crypto-currencies, real-estate settlement services, peer-to-peer lending, gaming platforms, and more.
Most attempts at solving the problem of detecting complex financial crimes concentrate on the problem of integrating disparate datasets, either by attempting to centralise them in a data lake architecture or by building data access APIs across distributed datasets. This is likely necessary in the long run, but there is an easier approach we can take in the short term that will meaningfully improve the financial system’s collective ability to detect crimes. Hard to believe? Read on.
At a fundamental level, detecting financial crimes is really about building statistical risk models that can accurately quantify the riskiness of an entity 

where 

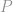

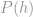



So how is the above relevant to the problem of detecting complex financial crimes?
Well, consider these facts:
- Every financial institution maintains tens to hundreds of risk models of different kinds on their customers as part of their normal course of doing business .
- The risk models between financial institutions can be quite different, giving us a diverse set of models when they are put together.
- Each of these financial institutions has legislative obligation to send a subset of their data to financial intelligence units (FIU) in each country. (For example, financial institutions send all cash transactions exceeding $10k, international fund transfers and suspicious matter reports to FIUs under the AML/CTF regime. Most law-enforcement agencies can also serve notices on financial institutions to obtain data on entities of interest).
- There are now confidential computing technologies that allow organisations to do joint computations on their collective data in a privacy-preserving manner. (See, for example, this article from Data61.)
Together, these provide essentially all the ingredients we need for different institutions in the financial system to come together to construct an ensemble model that approximates the Bayes optimal estimator for detecting complex financial crimes.
Let’s flesh this out with a concrete illustration. In the standard AML/CTF setting, you have a financial intelligence unit and a population of reporting entities (banks, credit unions, casinos, etc). Using privacy-preserving data matching techniques (see for example this paper), it’s possible for them to link up their shared customers and arrive at a configuration shown in the following diagram.

The first step in constructing an approximation to the Bayes optimal estimator is to sum the risk scores across all the reporting entities. In other words, instead of summing over all models in a hypothesis class, we sum over all the actual risk models being used in the reporting entities. This can be done in a privacy-preserving manner with a partially homomorphic encryption scheme like the Paillier Cryptosystem, as shown in the next diagram.
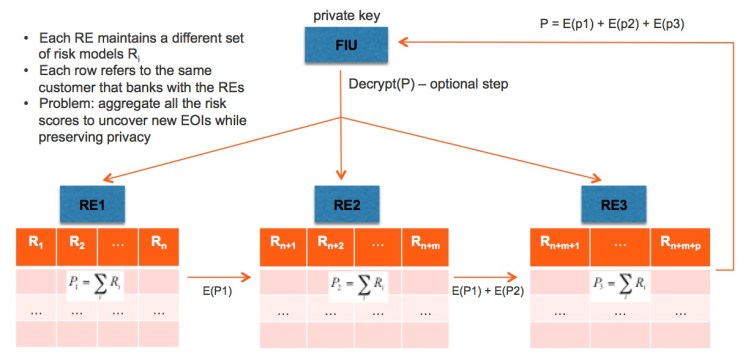
Here, each reporting entity (RE) simply sums up its local risk scores, encrypts the result using the FIU’s public key, adds it to the encrypted value from the previous RE in the chain if one exists, and then passes on the encrypted sum to the next RE. The last RE in the chain then sends the final encrypted result to the FIU, which then decrypts the data using its private key to obtain the resulting sum.
At this point, if we made the simplifying assumption that the weighting 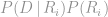

The problem comes down to having a good way of estimating the value of 
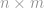

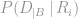
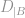


where 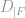


To incorporate the
So what would it take to build such an ensemble model? The title of this blog post deliberately a bit flippant to attract, I hope, the right level of attention. In practice, I think we are actually not that far away from making the above a reality. There are a few possible obstacles. To begin with, confidential computing is one area where technology has likely advanced beyond the boundaries of existing legislations. While the algorithms come with cryptographic guarantees on privacy preservation, the act of anonymous data matching may still require amendments to existing legislations. Also, in the short term at least, any attempt to build an ensemble model in the manner described in this article will require the willing collaboration of a network of financial institutions and relevant regulators or financial intelligence units. Such collaboration is likely difficult to achieve, but Australia is possibly in the best position to achieve such a result with the recent establishment of the Fintel Alliance, which brings together AUSTRAC, major financial institutions, and law-enforcement agencies in a public-private partnership. Here’s hoping optimism pays.

Very interesting vision Kee Siong. Would be interested to discuss the practicalities of PPRL per the paper you cite.
LikeLike