Suppose we have two entities P1 and P2 and P1 holds a training dataset 

Suppose further that we have a model learning algorithm A that takes in a training dataset and produces a model. (C4.5, Support vector machines, Elastic net, etc are examples of A.) The goal of privacy-preserving model learning in the context of A is to have an algorithm A’ that when jointly executed by P1 and P2 produces a model that would have been obtained from running A on 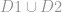
Looking at the problem formulation, it looks like we can easily construct privacy-preserving versions of many online learning algorithms. One of the simplest and most famous online learning algorithm is of course the Perceptron so let’s look at that.
To achieve privacy-preserving model learning in the context of the Perceptron, we simply get P1 to run Perceptron on D1 to produce a weight vector w1, which is then passed to P2, whereupon it runs Perceptron on D2 but using w1 as the initial weight vector. We can go back and forth between P1 and P2 until the weight vector stabilises, at which point the final weight vector is broadcast to both P1 and P2. At all times, the only communication between P1 and P2 is a weight vector, from which one cannot reconstruct any part of D1 or D2. Further, the final weight vector is obtained as if we are running Perceptron on
So that’s Perceptron. The simple scheme works for more modern algorithms like support vector machines (SVM) too. A state-of-the-art online SVM algorithm is Pegasos (Shalev-Shwartz et al, 2011). The primal form of Pegasos works in a similar way to Perceptron so can be handled easily. The dual form of Pegasos –you can see a quick description of the algorithm on Page 10 of this set of notes — is slightly more tricky to handle. In the dual form, the SVM model takes the form of a subset of the training data (these are the so-called support vectors.) For that reason, we cannot just pass the current model around to get a privacy-preserving version of the algorithm. The way to get around that is to “randomise” the current model before passing it on. Specifically, suppose 

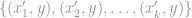

Note: Randomising the support vectors doesn’t work beyond the linear case; general Mercer kernels don’t have the linear property.
Note: The above talks about 2 parties but the algorithms obviously generalises to multiple parties.
Note: Another happy note is that Pegasos can be used for classification, regression, and outlier detection, giving us one sledgehammer to use for many different types of problems.
Question: How is this different from getting P1 and P2 to run, say, Pegasos on their individual datasets to obtain two models H1 and H2 and then do appropriate model averaging?
Answer: One way to combine H1 and H2 is to construct a new model 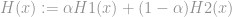
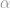
There’s a lot of other privacy-preserving algorithms out there. Basically, once people worked out how to compute inner products in the secure multi-party computation setting, the problem of designing privacy-preserving machine learning algorithms is largely solved because — thanks to our 25-year obsession with support vector machines and the kernel trick — most interesting machine learning algorithms can now be rewritten into a form that involves only inner product operations. (I’m being a bit flippant here and understating the significant research that has gone into the design of privacy preserving data mining algorithms.) The question I have is whether we need those more sophisticated algorithms, or do we only need something simpler like what I sketched out above?

One thought on “Privacy Preserving Support Vector Machines: A Simple Version”