Here is my attempt to map out the major classes of algorithms in Machine Learning, organised around the associated induction principles and learning theory. The usual caveats apply around this being biased towards my own experience.

At the highest level, we can distinguish between the Passive and Active learning settings. In the passive case, the agent receives data chosen by the environment and its job is to learn a model to predict what’s coming next. In the active case, in addition to receiving data from the environment, the agent has a set of actions it can take at every time step so its job is to learn a policy, a mapping from observations or states to an action, to maximise some measure of long-term reward. In sufficiently rich domains, one can have nested passive and active settings, like in state-of-the-art large language models and reinforcement learning agents.
The most standard passive setting is the supervised learning setting, where the agent is given a set of labelled examples of the form 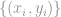
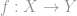


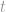

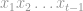

In general terms, given the labelled examples 

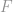

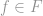

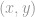

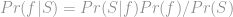

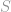

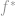

The first approach, exemplified by the Boosting, Random Subspace and MCMC families of algorithms, is to approximate
The second approach, called Maximum A Posteriori (MAP), to approximating 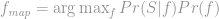

The third and final approach to approximating 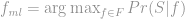
In the diagram, we have also shown a collection of techniques grouped under Representation Learning in the Passive setting. Compression methods include, among other things, clustering algorithms that are informed by the Minimum Description Length / Minimum Message Length principle, or algorithmic information-theoretic constructs like Normalized Compression Distance. Manifold Learning include the different non-linear dimensionality reduction techniques that generalise Principal Component Analysis, including Isomap, Spectral Embedding, multi-dimensional scaling, t-SNE, etc. Another class of algorithms for computing embeddings are Auto Encoders, which are typically 3-layer neural networks where the input and output layer have the same number of nodes but the middle layer has a smaller number of nodes. By training identity functions on such neural networks, we rely on principles like the Information Bottleneck method in the middle layer to generate good compressed representations of the training data. Graph neural networks, and their predecessors like word2vec, are yet another class of techniques for computing embedding of words / tokens into numeric vectors that are then used in further downstream processing. These embeddings can usually capture some contextual semantics of words / tokens based on what other words / tokens tend to co-occur in their neighbourhood. Together with the Attention Mechanism, embedding techniques like Auto-encoders and graph neural networks have been used very successfully as architectural components in Transformers that underlie a lot of the success behind large language models in recent years.
We now move on to Active learning. The simplest Active setup is the multi-armed bandit problem, where the agent has to come up with a strategy of choosing, at each time step, N different possible actions, each of which has an unknown payoff. This is a foundational problem whose solution requires optimally balancing exploration and exploitation, the former to get better data to estimate the payoff of each action, and the latter to achieve faster and better rewards using payoff estimates based on data collected so far. In the more general reinforcement learning setup, the agent can be in many different underlying states, which may or may not be directly observable to the agent, and taking an action in a state can result in a reward signal that is usually sparse, so most actions in most states result in no feedback from the environment. The goal of the agent is then to learn from data collected from interactions with the environment to learn an action-selection policy that seeks to achieve long-term average or discounted accumulated rewards. This optimisation problem can be formulated using the Bellman equation, and various stochastic dynamic programming algorithms have been proposed for solving the optimisation problem. Algorithms like Q-learning and Temporal Difference learning can solve the Bellman equation exactly for small state and action spaces. For problems with large state, observation, and action spaces, we usually have to resort to state abstraction techniques and / or function approximation techniques, the latter either approximate the value function, the Q-function, or the policy function itself. The different choices can lead to different algorithmic strategies, which are shown in the diagram.
That’s a bit of a whirlwind tour of major machine learning principles and algorithms. Hope it is useful to you.
