Privacy-Preserving Record Linkage (PPRL) is one of those problems that still doesn’t have a solid and widely accepted mathematical definition, perhaps because the problem of Record Linkage itself, especially the kind that doesn’t reduce to supervised learning through an abundance of labelled matches, still doesn’t have a solid mathematical definition despite thousands of papers published on the topic.
In the PPRL literature, Bloom Filters (see [Schnell]) is arguably the most widely accepted practical solution, although it’s known to be only “statistically safe” but not provably safe (see [Christen]). Most papers that advocate variations of Bloom Filters usually have a throw-away line that says PPRL can be done provably securely using Secure Multiparty Computation (SMC) or Homomorphic Encryption (HE) schemes, but that’s too expensive in practice. That may or may not be true — I am leaning towards not true, but that’s for a different article — but I am starting to think it’s probably quite inevitable that Batch PPRL, where Data Owners send precomputed data to a Linkage Unit, needs to be done using those expensive SMC or HE schemes unless we assume the Linkage Unit, which has access to a lot of information including frequency information and the similarity matrix (or the distance matrix), can be completely trusted.
To develop some intuition behind my suspicion — without a formal definition of PPRL, my conjecture can’t be stated formally let alone proved — let’s look at the simplest case of PPRL where each record is a digit, i.e. an integer between 0 and 9. In the two party case, Alice and Bob have two databases: 
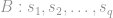


Obviously, any method that relies on hashing the digits, including Bloom Filters, are susceptible to frequency analysis so won’t work if the underlying distribution of digits has any exploitable structure at all.
Let’s look at the next natural method: secret sharing. I assume familiarity with Shamir’s Secret Sharing algorithm, which really just says that given an order-d polynomial 

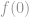
First Attempt:
Alice and Bob agree on two randomly generated integers a1 and a2 which is unknown to others. Alice then transforms each record 
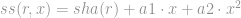
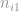

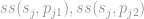


Both datasets are sent to the Linkage Unit (LU). To determine whether, say,
- uses
to recover a polynomial
- uses
to recover a polynomial
.

If 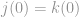

This is all fine except that it’s possible for someone with access to Alice’s transformed dataset to use the same LU protocol to check whether two records in the dataset are the same digit, which means frequency attack is possible.
The idea is to use a larger polynomial so access only to two records in the same dataset cannot be used to establish equality of digits. Alice and Bob agree on four randomly generated integers a1, a2, a3, and a4, which is unknown to others.
Alice and Bob both transform a record 
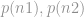

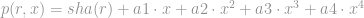


Now, for each possible record r from Alice and record s from Bob to be matched, the LU has two points from Alice, two points from Bob, and two points of its own, from which it forms two sets of five points to recover two polynomials and the digit equality computation proceeds as before.
This fixes the problem associated with the first attempt above because an external attacker can’t establish the equality of two records in Alice’s dataset because we would only have 4 points but we need 5 points to recover the secret.
But we now encounter another problem: The Linkage Unit can attack Alice (and Bob) by checking the equality of every pair of records in Alice’s dataset by adding its own share of points. This means, among other things, that frequency attack is still possible.
In case you are wondering whether there is a solution to avoid this attack by the LU, here’s an argument to show why this is futile. Essentially, the ability of the LU to establish the equality of all pairs of digits (r,s), where r is from Alice and s is from Bob, implies an ability by the LU to establish the equality of all pairs of digits (t1,t2) where both t1 and t2 are from Alice or from Bob (under the mild assumption that Alice and Bob’s datasets contain occurrences of all 10 digits).
To see why that is true, consider two records r1 and r2 from Alice. If r1 and r2 are the same digit, then there exists a record s from Bob where the LU can show r1=s and r2=s. By transitivity of equality, the LU can therefore establish r1=r2 (without having to resort to any special attack operations on the underlying shares of secrets.) The argument applies symmetrically to any two records from Bob too.
This means the LU needs to be a trusted entity, and there is no way around that. The above is a very special case of the sort of attack that can be done on a similarity matrix. From here, it’s hard not to accept that, if the LU cannot be completely trusted (which is already true in the honest-but-curious setting), then any scheme that allows LU access to the (unencrypted) similarity matrix, either in part or in full, cannot really satisfy any reasonable definition of Privacy-Preserving Record Linkage.
We are then led down two possible paths. In the first instance, we can use Homomorphic Encryption techniques to allow the LU to compute the similarity matrix in the ciphertext space, which is then passed on to a trusted entity for decryption. Alternatively, we give up on the idea of doing PPRL in batch mode, and there are pretty natural solutions from, for example, the Randomised Encodings of Functions framework (see [Applebaum]) that we can use to do PPRL in interactive mode. More on those two ideas in future posts.
[Applebaum] https://eprint.iacr.org/2017/385.pdf
[Christen] http://users.cecs.anu.edu.au/~christen/publications/christen2019data61-slides.pdf
[Schnell] https://computation.curtin.edu.au/wp-content/uploads/sites/25/2017/10/Schnell_2017_Curtin_CS_2.pdf
