A challenge with fraud-detection problems in many cases is the lack of any meaningful collection of labelled data for supervised-learning approaches to work. Two things practitioners do to tackle the problem are statistical profiling, usually via domain-specific business rules, and statistical outlier detection, sometimes augmented with non-trivial models of what constitute “normal” behaviour. There is a third pillar we can rely on in practice: the use of a hierarchy of models, each focussing on a specific dimension of possible fraud, to surface problems that are hidden in a number of weak signals that, on their own, don’t raise enough suspicion.
Let me illustrate this third pillar with a case study in waste, abuse and fraud (WAF) detection in health insurance.
Health insurers care primarily about Over-charging and Over-servicing by healthcare providers (doctors, pharmacists, specialist). The following illustrate how we can approach the problem of detecting WAF using a hierarchy of models, where the units of analysis start from line items in medical bills and move on to claims, customers, agents, doctors, and finally groups of individuals for collusion detection.

In the framework, low-frequency WAF activities are tackled using anomaly detection algorithms like Local Outlier Factor (LOF) and One-class Support Vector Machines (SVM). Systematic WAF activities – the two main categories being Over-charging and Over-servicing – are tackled using probabilistic business rules.
We will now see examples of a few of the models described to get a feel of the general framework.
In the context of detecting Over-servicing at the level of individual line-items in a medical bill, we can flag a line-item in a bill if the particular combination of line-item, diagnosis, and procedure occurs rarely, if ever, in all the other bills. (Some standardisation of line-item descriptions across different health providers is usually necessary for this to work, and that’s a small interesting data science problem in itself.) Here is a simple illustration of the sort of things one can detect using this method: an eye-related service looks rather strange in light of the diagnosis and procedure of this medical bill.
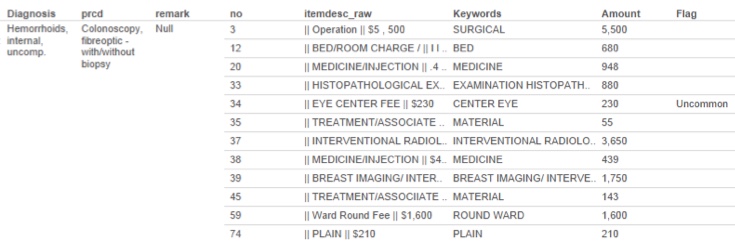
On its own, this is just a little oddity that may or may not be important. But if one performs aggregation of this simple model at the higher levels of provider, clinic / hospital, or hospital group, it’s possible to detect whether some systematic over-servicing practice is being conducted.
At the aggregated level of customers, agents, providers, and groups, where there may be many different variables some of which comes from models at lower levels, one can use techniques like one-class support vector machines to rank entities based on an outlier-ness score. For further detailed analysis, a radar chart is usually a good way to visualise the multiple dimensions that need to be considered, and here is an illustration in the health insurance context, comparing a specific outlier instance with the baseline “average profile”.

Beyond individuals (a customer, an agent, or a doctor), one can use a relatively simple shared-activity matrix to detect possible collusions. One hypothesis in the health insurance context is that a colluding agent-doctor pair will exhibit a disproportionately high number of shared claims through a common pool of customers, where each customer may itself be measured using a customer outlier score that combines multiple models like that shown above. A matrix of doctors vs agents like the one below, where the cells show shared customers, can be effective at detecting such collusions.

In the matrix,
- one-doctor, multi-agent networks show up as horizontal lines in the matrix;
- one-agent, multi-doctor networks show up as vertical lines in the matrix; and
- multi-agent, multi-doctor networks, if there is any, will show up as the outline of a square in the matrix; the larger the network, the larger the square.
It is not hard to write an algorithm to find all such networks in the matrix once it’s computed.
I think this hierarchical modelling approach to fraud detection has much wider applications beyond health insurance, including the anti-money laundering domain, which shares many of the challenges described above around data sparsity, especially labelled data, and the resulting prevalence of weak signals.
