Having spent nearly a decade studying the design and implementation of declarative programming languages in a previous life, I get a bit frustrated whenever I see people getting religious about programming languages and platforms. In the data science circle, an active discussion is around Scala (on Spark) vs SQL (on parallelised relational databases). They are both useful platforms for data science, each with its own strengths and limitations. A complete data science environment should support both, but I sometimes see people make the conscious decision to choose only one in the naive belief that one or the other is the one “right” platform.
In one camp, I see software engineers interpret NoSQL as No more SQL rather than the intended Not Only SQL and downright dismiss SQL as a “legacy language” after embracing Spark. In the other camp, I see data analysts dismissing Spark as yet another fad that is only used in internet companies but which is never going to be “enterprise-ready”.
Both viewpoints are of course misguided. In particular, I think people with such views do not have a proper understanding of where computer science comes from, which is explained in the theory of computations. (Perhaps unfortunately, the theory is usually only taught in post-graduate courses.)
There are essentially three different but equivalent ways of defining computability. Most of us are familiar with Turing machines, from which the von Neumann machine is derived. Most modern computers have a von Neumann architecture, and from the machine and assembly languages of these computers come the family of imperative programming languages like Fortran, C, and Pascal. The second formalisation of computability is based on Alonzo Church’s lambda calculus, which evolved into higher-order logic that in turn serve as the theoretical foundation of functional programming languages like Haskell, Miranda and ML, with beloved features like higher-order functions (functions that take functions as arguments or return function as result) and interesting type systems. The third formalisation of computability is based on first-order logic or the equivalent relational algebra, from which we obtain declarative logic programming languages like Prolog (familiar to most AI students) and SQL (the popular database query language) that have automated inference mechanisms built-in. All three formulations of computability turn out to be equivalent: any computation that can be expressed in one can be expressed in the other two. Further, these formalisations capture the ultimate essence of computability, in the sense that if a mathematical object is computable, then it can be computed in any one of these three formalisms.
Every programming language and platform is essentially a derivative of one of these three formulations of computability.
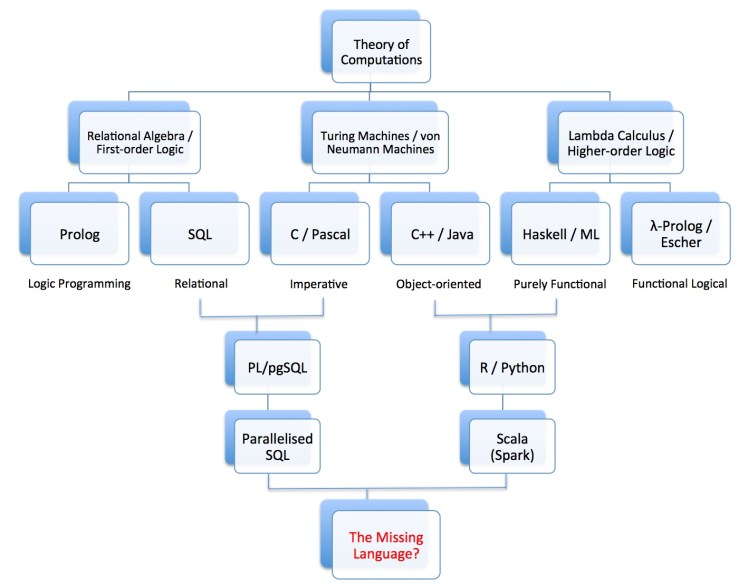
In the diagram above, I have listed some representative families of programming languages and platforms and traced their roots to the three theories of computations. (No attempt was made for the diagram to be exhaustive.) Most early programming languages sit squarely within a paradigm, either imperative, functional, or logical. Most modern languages sit at the intersection of two paradigms. In the data science area, in particular, we have languages like R and Python with both imperative and functional features, and languages like PL/pgSQL with both imperative and logic-programming features. From those languages evolved parallelised procedural SQL and Scala that run on parallel computers, for both scale-up and scale-out architectures, that are now the subject of active R&D in the design of data science platforms and programming paradigms.
Not a day goes by without yet another data science platform and language being invented these days. That is all very good for scientific progress, but all that activities and inventions can be confusing and overwhelming to data scientists and data engineers that do not understand where it all comes from. That’s why I decided to write this post. I hope it helps people understand. In the same way that a computational theorist exploits how computations can be expressed in different formalisms to prove deep theorems about the essence of computability, we data scientists and engineers should seek to learn the many different ways of representing data and performing operations on them instead of trying to find the “one true way”, which is a fool’s errand. In diversity we will prosper.
Another note worth making is that because there are many more combinations of features to explore when we start to bring the different computational paradigms together, we can expect the number of programming languages and platforms to continue to grow and the half-life of each system to get shorter and shorter. This of course has important implications for organisations: those that commit to one platform with a heavy investment will suffer from loss of agility quickly in time, and those that invest in adaptability and resilience, by skilling up its people with knowledge of the essence of computation and programming, will be the ones that survive.
Lastly, I would also like to take the opportunity to throw down a challenge to the community: let’s work on a new platform and language that combines the best features of the imperative, functional, and logical paradigms of computations!

Thanks great bblog post
LikeLike