In Part 1 of this blog article, we looked at the problem of tokenising a URL as an intermediate step towards learning user preference models from browsing histories. In Part 2, we next look at the problem of learning a URL classifier model from the preprocessed Shalla dataset using Support Vector Machines.
A standard way to represent textual data is to construct term-occurrence vectors. The way it works is that we will have a dictionary of features or ‘important’ words of size m and represent a bag of words 



Linear support vector machines are effective and popular classification learning tools, well suited for problems like text classification. Formally, given a training set 
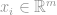
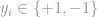
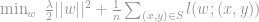
where 

Intuitively, in the SVM formulation, we seek a model 
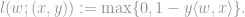
Standard implementations of SVM have time and space complexity that is quadratic in the size of the training set, which makes them infeasible for large datasets. In this project, we use the time- and-space efficient Stochastic Gradient SVM algorithm introduced by Leon Bottou, which solves the SVM optimisation problem approximately with a stochastic gradient descent approach. This award-winning algorithm is known to work well in practice and the version we use is the implementation available in MADlib, which can be called in SQL with the following syntax:
SELECT
madlib.lsvm_classification(‘training_table’, ‘model_table’, ...)
The main advantages of using an in-database algorithm are
- the algorithm can exploit parallelism to scale to large datasets, unconstrained by available main memory;
- there is no movement of data in and out of the database environment, which shortens the analytics life cycle; and
- the resultant URL classifier model comes in the form of a table in the database, which simplifies the deployment and operationalisation of the model.
Classifier models obtained from linear SVM are pleasingly easy to interpret. The table below show the words with the highest and lowest weights in the model obtained for the Shopping class from one run of the algorithm. (There are 23,214 words in the features dictionary.)

As can be seen, words that are indicative of a Shopping website got high weights and words that are not indicative of a Shopping website got low weights. To classify a URL like http://jewellery-insurance.com, which gets tokenised into { jewellery, insurance }, we simply add up the word weights 2.70 + (−2.20), which gives us a positive score of 0.5 and the URL is classified as a Shopping website.
The SVM formulation given above is designed for binary classification, i.e. two classes. There are a number of ways to handle multiple classes. We adopt the one-vs-all approach, which works as follows. Suppose there are three classes: Shopping, News, and Educa- tion. We turn the training set S into three separate training sets: SShopping , SNews , SEducation , where SShopping is the same as S except that the labels are changed to +1 or −1 depending on whether the class is Shopping or not, and similarly for SNews and SEducation. A model is learned on each training set and classification is done by assigning the class that gives the highest score from among all the models.
The final URL classifier works in two steps:
- If a URL has a match in the Shalla dataset, return the class.
- Otherwise, we use the SVM model to classify the URL.
This concludes the description of a solution to the problem of understanding customer browsing behaviour through the construction of URL classification models. The models have reasonable accuracy (as can be verified through cross validations) and, with an appropriately designed business-validation regime, can be hardened to production-grade models for deployment.
