Content-based recommendation engines are typically done in two steps. In the first, a user-preference model is constructed using a set of predefined features. (For example, in the context of retail, we may have features like Price Sensitivity, Promotion Sensitivity, Coupon Redeemer, Calorie Counter, Working Mums, etc.) In the second step, products are mapped, either directly or indirectly, to the same set of predefined features and then matched against users likely to be interested in them.
This general scheme can work well in practice but it has a downside: defining a set of features that is sufficiently rich and universal for characterising both customer preferences and product descriptions is usually a time-consuming and manual effort that requires good domain knowledge and, for those companies with an ever-expanding product range, regular updating. The difficulty of this feature-engineering step became evident to me over time because this is precisely the step where many companies got stuck and first approached us for help. (Many companies never got past using basic first-level features like gender, age and other socio-demographic factors that aren’t very useful for product recommendations. The ones that got to second-level features like Promotion Sensitivity, Price Sensitivity typically find themselves spending a lot of time thinking about how to match a wide variety of products and marketing campaigns with different consumer segments obtained from their second-level features. For example, what exactly do I recommend a promotion-insensitive, calorie-counting, working mum?)
Sure enough, there are vertical-specific solutions that are designed to solve some of these problems and there is a whole industry behind this. I won’t discuss those in detail in this blog piece. What I want to do instead is give a description of a generic recommendation engine that
- can work across multiple verticals with minimal change;
- will produce decent recommendation results with minimal initial effort;
- can learn to adapt to new preferences and consciously trade-off exploration and exploitation while in production; and
- can be substantially automated.
The design of this generic recommendation engine is based on the simple observation that both customer preferences and product descriptions, in all verticals known to me, can be adequately characterised using a bag-of-words representation with a suitably defined dictionary. After all, a customer’s preferences are expressed quite explicitly in the words that appear in the products she bought/researched and also activities that she was engaged in, and a product description is nothing more than a collection of words. Note that we are simply applying here concepts familiar from the Vector Space Model from text analytics.
We now describe the individual components of the recommendation engine.
Customer Preference Modelling
The following diagram shows the general preference-modelling scheme.

Each customer is associated with a bag of (key)words that appear in the sum total of her various activities, each captured in the form of a data source. (The different data sources can be weighted if necessary.) For example, in the context of a telco, one data source could be websites visited by the person and past search terms, another could be social media posts and a third could be meta-data on Youtube videos viewed. For a retailer, data sources can include actual historical purchases (textual product descriptions) and past responses to campaigns and promotions.
A customer’s personal preference model is represented by the person’s term-frequency-inverse-document-frequency (TF-IDF) vector (or its improved cousin ESA vectors) obtained from her associated bag of words. A customer’s peer preference model is represented by the average TF-IDF vectors of all the people in the person’s peer group, which can be obtained through, for instance, common clustering or nearest-neighbour algorithms. A key design in the above scheme is the dictionary, which is typically constructed using a combination of statistical means (high frequency words across the entire dataset) and domain knowledge.
The preference models so-obtained serve as the initial preference models in our system.
Product Recommendation
We now address the product-recommendation problem. Specifically, for each customer, given
a preference model where D is the dictionary
- a set of products

we want an algorithm that can produce a ranking over P.
This can be easily done by mapping each product description onto the same underlying TF-IDF representation and comparing the resultant vectors with a suitable distance function. Specifically, product ranking in our case is done using the following product preference score
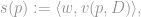
where v(p,D) is the TF-IDF vector representation of product p using dictionary D and 
Online Adaptation While in Deployment
In practice, we also want our recommendation engine to continue adapting while in deployment. The user preference model w as described above serves as an initial model in our system and it can be further adapted while in production based on actual user feedbacks using online-learning algorithms. A particularly suitable choice in our case is the Pegasos algorithm (Shale-Shwartz et al, 2011), a state-of-the-art online linear support vector machine algorithm. (Linear SVMs are known to work well on high-dimensional text vectors.)
The system will make product recommendations based on the preference scores given earlier. Every time the system receives a customer feedback (x,y), where x is the product recommended and y is the customer’s rating (good or bad), the customer preference model w can be adjusted as follows:

Recall that <w,x> is the predicted preference score of product x. The algorithm seeks to adjust w so that the system predictions will increasingly match the customer’s feedback over time. In the algorithm, 


Model/Channel Selection
We have seen how an initial user preference model can be constructed from historical textual data and how that model can be used to make product recommendations and be adapted over time based on actual user feedbacks. There is a final piece of the puzzle that needs to be tackled.
In many real-life applications, there can be multiple product recommendation models (for example, we have two in the scheme described above: a personal preference model and a peer preference model) and multiple communication channels with customers (for example, emails with embedded links, direct phone calls, etc). The problem of working out which combination of models/channels works best for a customer is a classical N-Armed Bandit problem. We need to try out the different options and collect enough statistics about them to work out the optimal combination, an exercise in balancing exploration and exploitation. We propose using the UCB policy (Auer, Cesa-Bianchi, Fischer, 2002) in the system. At every decision step, the algorithm picks, among the available choices, the model/channel j that maximises

where 

- Every model/channel will eventually get chosen an infinite number of times.
- The best model/channel (highest average reward) will get chosen exponentially more often than others over time.
The proof is non-trivial but the implementation is straightforward.
That concludes our description of the system and there you have it, a generic, easy-to-implement product recommendation engine that can be used in almost any vertical by working directly on textual data, is scalable, and one which can learn and adapt while in deployment as well. Let me know if you find it useful and/or have ideas about improving it.
